�ھ�����4��ƪ����չ���й�����������
�����ڰ��·ݣ���������д��һƪ����ⲿ���ݷ��������£�һ���ֶ��߿������ĺ�����߷�ӳ��˵���ⲿ���ݵķ���������ԭ�е�ֻ�����ҵ�ڲ����ݷ������û����ݡ��������ݡ��������ݵȣ����ʣ�����ҵ����������Դ������������ѵ�����£������ܸ���Ʒ����Ӫ��Ӫ���������벻�������ϣ�Ϊ���ݻ�����ҵ����������һ�ȴ�����
�������ڱ������ڵ�����������һ����ữ��������������������˾�����ڴ����ݷ�����ת�����ݲ�Ʒ�ں��ɱ�����漰��������������������ʵ��Ӧ�ó������ɴˣ����߽������е����ɣ���ʵ�ʰ�������ʽ���г��֣��漰�����ݲɼ���������ϴ�����ݷ����ٵ����ݿ��ӻ���һ�������̷�������������������չ���ⲿ���ݷ�����ǿ�������������DZ��ĵ�д����ܣ�
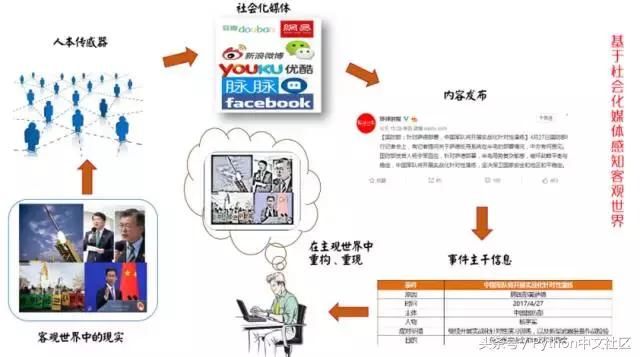
�������ֽ����ݱ�ը����Ϣ������ݬ����Ļ�����ʱ����������ʱ�̲������ڻ�������ữ�ġ���Ϣ��֮�У�����ɱ���ı������ĵ���Ϣ������Ю����Ҳ����˵����ữ�ϵ���Ϣ����ʵ�����е�ÿ���˶����ش�Ӱ�죬��ữ�����Ǽ���˽���ʵ����������������һ�洰��������ÿʱÿ�̶����ܵ�����Ӱ�졣���ڡ���ữ����������ݣ���ο����ɻ����������Social Listening����ữ�С��������м�ֵ����Ϣ��������������Ҳժ�Ը��ģ�
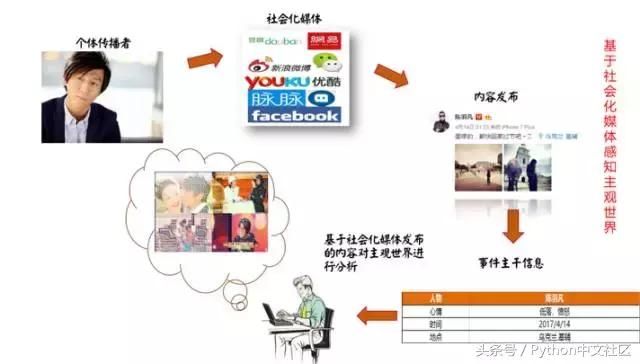
�����ɴˣ���ữ����ʵ���������һ�澵�ӣ�����Ҳ���һ��Ӱ�����ǵ���Ϊ��������ǶԸ������е���������������Ϣ���з��������˿����˽������ķ�չ���̺���״�������ԶԸ��������Ⱥ��Ϊ����һ���̶ȵ�Ԥ�С�
�������ڴ����������Ϊ��������ҵ�ߵı��������һ�»�������ҵ��һЩ��״����һ�����ҵ��ڻ�������������ҪӰ�������ϴη������ǡ����˵��Dz�Ʒ����������ο��� �ɻ�����Ϊһ���ϸ�ġ������ڿ͡����㻹�������ⲿ���ݵķ�������������α����뵽���ǻ�������
����������������2012��5�£���һ���ۺ����ʴ�����Ϣ����Ⱥ����ƽ̨����ƽ̨רע�ڹ���ԭ������ȡ�Ϭ�����ʵ���ҵ��Ѷ��Χ�ƴ��´�ҵ�Ĺ۵���������뽻�����������ĺ��ģ��ǹ�ע����������ͳ��ҵ���ںϡ�һϵ�����ǹ�˾��������˾�봴ҵ����ҵ��������켣����ҵ��ϫ�Ķ��������ơ�

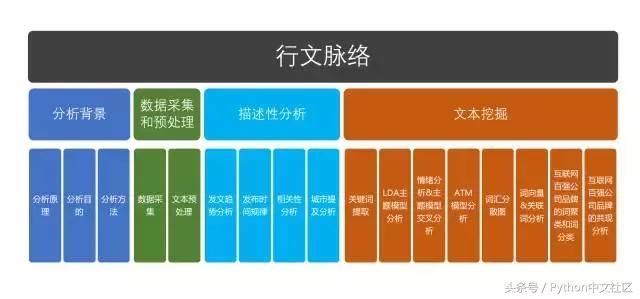
����ʹ���������ݷ������ߣ����߽�����2�����ݷ�������һ���ǽ�Ϊ��ͳ�ġ������ֵ�����ݵ�������ͳ�Ʒ��������Ķ������ղ�������ʱ��ά���ϵķֲ�����һ���DZ��ĵ���ͷϷ---���ε��ı��ھ����ؼ�����ȡ����������LDA����ģ�ͷ�����������/�����ʷ�����ATMģ�͡��ʻ��ɢͼ�ʹʾ��������
��������ʹ������ɼ������Ի�������ҳ�����£�������ȫ�������£���չʾ����ҳ����Ϣ�����ྫ��ϸѡ�ģ��ܾߴ����ԣ������ݲɼ���ʱ������Ϊ2012.05~2017.11������41,121ƪ���ɼ����ֶ�Ϊ���±��⡢����ʱ�䡢�ղ��������������������ݡ��������ơ�����顢���߷�������Ȼ������˹���ȡ4����������Ҫ��ʱ��������ʱ����ܼ��������ݳ����������������������������������յõ�����������ͼ��ʾ:
�������ݷ���/�ھ�������һ��������ɣ���Garbage in, Garbage out������������Ԥ����������ȡ������ķ��������˵��������Ҫ�ġ����ĵ����ݹ�����Ҫ�Ƕ��ı����ݽ�����ϴ����������Ŀ���£�
����Ҫ�����ı��ھִ�����Ϊ�ؼ���һ������ֱ��Ӱ������ķ������������ʹ��jieba�����ı����зִʴ���������3��ִ�ģʽ����ȫģʽ����ȷģʽ����������ģʽ��
������ȫģʽ��: ����/ ����/ ��������/ רע/��/ ��ữ/ ������/ ��ữ������/ ��/ ������/ Ӧ��
��������������ģʽ�������ˣ����飬�������飬רע���ڣ���ữ�������ݣ���ữ�����ݣ��ģ���������Ӧ��
�������������ʣ���the������a������an������that�������㡱�����ҡ��������ǡ�������Ҫ���������������ԡ���
����ȥ����Ƶ�ʡ�ϡ�д�����Ժ���������ģ�ͣ�LDA��ATM��ʱʹ�õģ���Ҫ��Ϊ���ų��������������岻��Ĵʻ㣬���յõ�������ͣ�ôʵ�Ч����
����Bigrams��Ϊ���Զ�̽����ı��е��´ʣ����ڴʻ�֮��Ĺ��ֹ�ϵ---��������ʾ���һ�����ڳ��֣���ô�������ʿ��Խ�ϳ�һ���´ʣ����硰���ݡ�������Ʒ����������һ������ڲ�ͬ�Ķ������ô��������_��Ʒ���������Ƕ��ߺϳɳ������´ʣ�ֻ��������֮��������»���. �����Է���
�����ò����У�������Ҫ����ֵ�����ݽ��������Ե�ͳ�Ʒ����������ڽ�Ϊ��������ݷ������ܳ�һЩ���⣬����֪��Ȼ���������ݷ�����4�����ͣ�������ο����ɻ�����Ϊһ���ϸ�ġ������ڿ͡����㻹�������ⲿ���ݵķ��������ĵ�һ���֡�
��������ͼ���Կ�������2012.05~2017.11�ڼ䣬�Լ���Ϊ��λ����ҳ�ķ�������������������ھ�ֵ1800���²���������2016���������������������
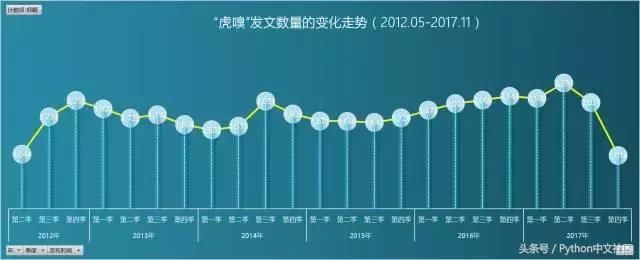
������ͼ���Ǹ�ʱ������ղ������������ı仯������������ı仯��㳲�����������ղ���һֱ�������У���������2017��ĵڶ����ﵽ��ֵ���ղ�����һ���̶��Ϸ�ӳ�����µĸɻ��̶Ⱥͼ�ֵ�ԣ�������Ϊ�м�ֵ�����²Ż�ȥ�������ղأ������Ķ�����Ӣ������˵����������������ڲ�����ߣ�����ߵ�������������
�������ߴ�ʱ��ά������ȡ�����ܡ��͡�ʱ�Ρ�����Ϣ��Ҳ���ǿ����ᵽ�ġ��˹�����������ȡ�����������·ֲ��������ڡ��ܡ��͡�ʱ���ϵĽ���������õ���ͼ��
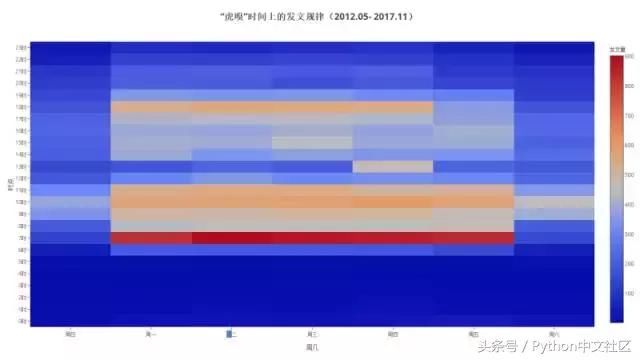
������ͼ��һ������ͼ��ɫ����ɫ�ϵ���ů���������ֵ���ɴ��С�������ԵĿ��Կ������м���һ����ɫ�����Ե������ɡ�6ʱ~19ʱ���͡���һ~���塱Χ�ɵľ��Σ�Ҳ����˵������ʱ����Ҫ�����ڹ����յİ��졣���⣬��һ�������ڼ䣬6ʱ~7ʱ���ʱ����Ƿ��ĵĸ߷壬˵�������������Ӫ��Ա�������ڹ����յ��峿�������£���Ҳ����������Ⱥ��λ---TMT�����ҵ����ҵ�ߡ�Ͷ���ˣ������е��������г�����ϰ�ߣ�ϲ���ڸϵ������������Ĺ������Ķ�����ѶϢ�����ĸ߷廹��9ʱ-11ʱ����߷壬��Ϊ����ǰӦ�Զ�������ʱ����Ķ�������17ʱ~18ʱ����ǰӦ�Զ����°�ʱ����Ķ���
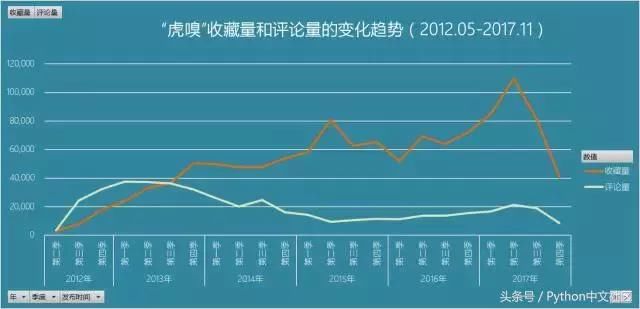
��������һֱ�ܺ��棬���µ����������ղ����ͱ������������������Ƿ����ͳ��ѧ�����ϵ�����Թ�ϵ�����ڴˣ������Ƴ��ܷ�ӳ����������ϵ������ͼ��
������Բ�ε����ݱ�������������������ϻ�������ͼ������ͼ�У����������������������DZ�����������������С�������ǵĴ�С����ɫ����ӳ����ɫԽů����ֵԽ�������Խ����ֵԽ������ͼ���Կ����������������ϴ�����£����ֲַ�������������6000�֡���������20�������ɵ������ڡ��������ϵ���ҵ��Ѷ���´���ԭ������ȵ��ص㣬����ƪ���г�����ζ���ܰ����鱳�������ȥ��������������ұ���Ҫ�ܹ������ˣ��������ߵĴ����Ķ������ʳ��ȱ��������ƪ������������һ�㡣
���������������߽��ղ������������ͱ��������������������Ƴ�һ��3D����ͼ��X���Y��ֱ�Ϊ��������������������Z��Ϊ�ղ����������������ɵ�
������ͨ����ת���3ά��Suceͼ�����ǿ��Է����ղ������������ͱ�����������������֮�����ع�ϵ��
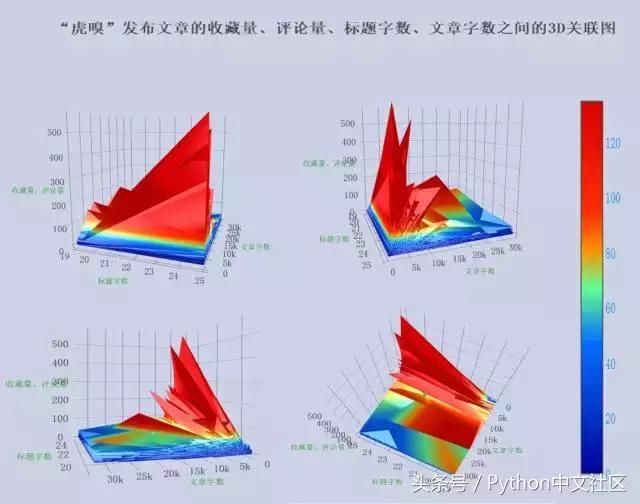
����ע�⣬��ͼ����ֵ��ʾ��ǰ�漸��ͼһ������ɫ�ϵ���ů�����ʾ��ֵ���ɴ�С��ͨ����ת��ά�ȵĽ��棬���Կ�������������5000�����ڡ���������15�����ҵ��ղ������������γɵĽ�����֡���ɽʽ�����壬���������ղ��������������
�������������ͨ������һ������ȫ��1~5�߳��еĴʱ�����ȡ������Ԥ��������ı��еij������ƣ������ἰƵ�εĴ�С�����Ƴ�һ�ŷ�ӳ�����ἰƵ�εĵ����ֲ���ͼ��������ӵ��˽�������л������ķ�չ״����һ����е��ἰ����������ҵ����Ʒ��ְλ��Ϣ�ҹ�������һ���̶��Ϸ�ӳ�ó��л�������ҵ�ķ�չ̬�ƣ���

������ͼ��ӳ�Ľ���ȽϷ��ϳ�ʶ��������㺼��Щһ�߳��е��ἰ������࣬�����ǻ�������ҵ��չ������ֵ��ע����ǣ������ǵ����Ĵ����������������Ⱥ���������Ϻ�������ʡ���Ͼ������������ݡ����ݡ���ͨ���γǡ����ݡ���̩�ݣ��㽭ʡ�ĺ��ݡ����������ˡ����ݡ����ˡ�����ɽ��̨�ݣ�����ʡ�ĺϷʡ��ߺ�������ͭ�ꡢ���졢���ݡ����ݡ����ǣ����ֳ��ϸߵ��ȶ�ֵ��ֱ��˵����Щ�����ڻ�����������Ѷ�����е��ἰ�����϶࣬��Ϲ������ߺ͵������أ��������������ͼ�з�ӳ�������ʵ��
������Ҳ���dz���֮������ͬʱ���ֵ�Ƶ�ʣ���һ���̶��Ϸ�ӳ�����м侭�á��Ļ������ߵȷ������ع�ϵ������Ƶ��Խ�ߣ�˵������֮�����ϵ���̶ܳ�Խ�ߣ���ȡ���Ľ�����±���ʾ��
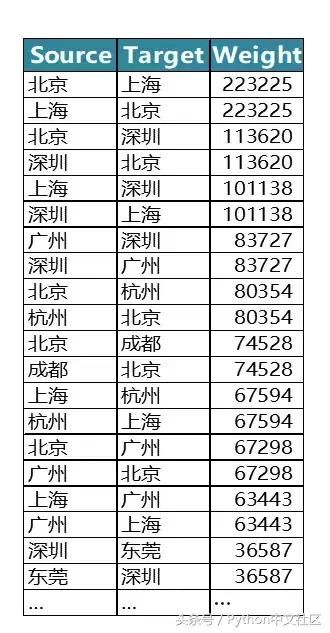
�������ڻ������ϵ����´���漰��ҵ�����ߡ���ҵ��������ݣ�������ֳ���֮��Ĺ��ֹ�ϵ��ӳ���Ǽʼ�����Դ����Ա������ҵ����Ĺ�����ϵ������̬ͼ�У���Ҫ��ӳ���DZ��Ϲ���������е���Ŧ�ڵ㣩֮����������ϵ���⼸��һ�߳������еĵ����������Ρ������������ܼ��������������й�����3������Ⱥ�������������˵ij���Ⱥ��
���������ı��ھ�������֪ʶ����ο���������Ӫ���ݷ����У��ı�����Զ����ֵ�ͷ�����Ҫ�����ϣ�����������Ӫ�У�Ϊʲô�ı�����Զ����ֵ�ͷ�����Ҫ��һ��ʵ�ʰ��������������£��������ĵ��ı��ھ���Ҫ�漰��Ƶ��ͳ��/�ؼ�����ȡ/�ؼ����ơ����±�����ࡢ�������ݾ��ࡢ��������LDA����ģ�ͷ�����������/�����ʷ�����ATMģ�͡��ʻ��ɢͼ�ʹʾ��������
�������ڹؼ�����ȡ������û�в�ȡ��Ƶͳ�Ƶķ�������Ϊ��Ƶͳ�Ƶ����ǣ�һ�����������г��ֵĴ���Խ�࣬������Խ��Ҫ����������߲��õ���
������termfrequency�Cinverse document frequency���Ĺؼ�����ȡ����������������һ��/�ʶ���һ���ļ�����һ�����Ͽ��е�����һ���ļ�����Ҫ�̶ȣ���/�ʵ���Ҫ�Ի����������ļ��г��ֵĴ������������ӣ���ͬʱ�������������Ͽ��г��ֵ�Ƶ�ʳɷ����½���
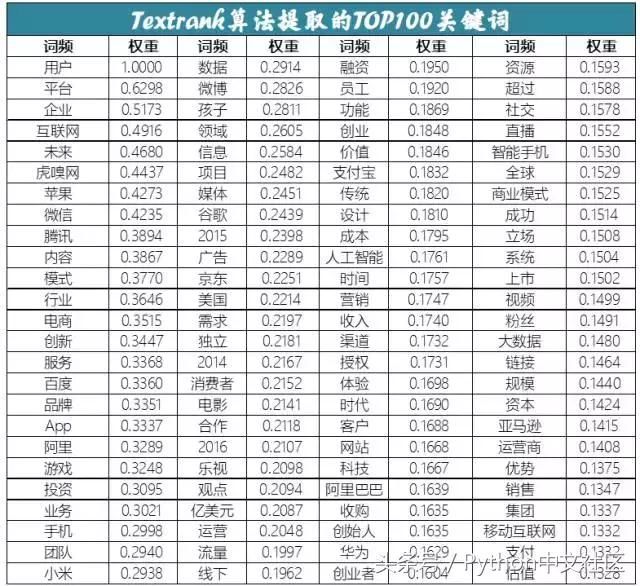
��������ѡȡTOP500�ؼ��������ƹؼ����ơ���Ϊ�����������Դ��Ӣ������ʫ��Siegfried Sassoon������ʫ�䡰In me the tigersniffs the rose�������ͻ���ϸ��Ǿޱ�������Դ����ԡ�����Ǿޱ��Ϊ�������Ҳ������ʵĻ���Ǿޱ�Ļ��棬���������Ľ���è��Ϊ������������£�
�����ղ���Թؼ��ʵķ����Ϊ���ԣ�����Ϊ���֣�������ʧƫ�ģ��ﲻ��ȫ���Ч������ˣ����߲���LDA����ģ�������ָ������е�DZ�����⡣����LDA����ģ�͵����ԭ������ο������ɻ����ô������ı��ھ������조��������������ҵ��״�����ơ��ĵ�4���֡�

�������Կ����������ı�Ԥ����������ϱȽϣ�ͨ��ÿ�������µġ�����ʡ������Ժ����Ĵ���10����Ⱥ�б������������⣬����������3������������۵������ÿ��topic�°���2�����⣩�����ⲻӰ����ߵĺ�������������������±���ʾ��
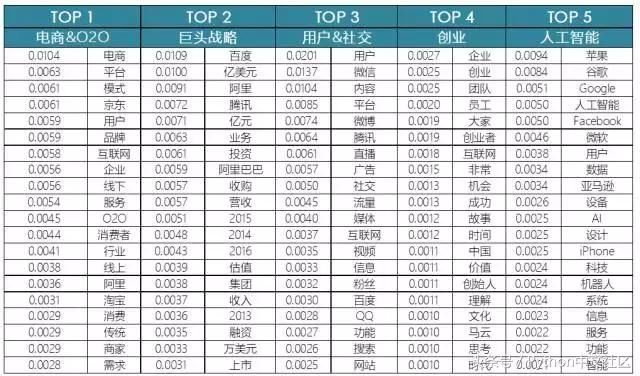
������ ���������2�����֣����������ƽ̨���Ա��������ȣ��ϵ����ۣ�O2O(Online��������Offline��������)���̼�ͨ����ѿ����꽫�̼���Ϣ����Ʒ��Ϣ��չ�ָ������ߣ������������Ͻ���ɸѡ����֧�������½���������֤���������顣
�����������ƶ�������ʱ���������������ݵIJ��ϻ��ۺ�Ӳ��������ͻ���ͽ���������ʱ����Ȼ���٣���֮�����Ļ����˹����ܣ���������ʱ�¹�����IT��ͷ����Ľ��㡣
�����������ֻ����ռ����ƶ�������ʱ������Ĵ���֮һ��2012�������������磨���������ֻ���ҵ������ѹ�������磨���������ֻ���ҵ���������������ֻ�Ʒ����������ƻ����С�ʹ��ӵ�ÿһ���ֻ������������ڻ�����������һƬ���顣
������Ӱ���Ļ���ҵ��Ϊ������ͦ����������ҵ�������������ʱ���Ŀ�⡣�ڽ����ʱ����Ӱ��ҵ��ײ�������ı������й�Ӱ�������г��Ŀ������𡣹��������IJ���������Ʊ���Ŵ��¸ߣ�ֱ�Ӵ̼��Ź���Ӱ�Ӵ�ҵ�����������ı�����Ƭˮƽ���ɴ˵�����һ����Ӱ�Ӽ���������������ġ������ط��ա������ع����ж�������ս��2����
���������������ڣ�ITFIN����ָ��ͳ���ڻ����뻥������ҵ���û�������������Ϣͨ�ż���ʵ���ʽ���ͨ��֧����Ͷ�ʺ���Ϣ�н��������ͽ���ҵ��ģʽ��2011����������������������������ͻ���ͽ���ʵ���ԵĽ���ҵ��չ�Σ�����������У����ڻ��������ڳ��ֳ����ֶ�����ҵ��ģʽ�����л��ơ��������£�����������ʡ����ӡ���Ȼ��Ŀ����2014�����Ծͤ�������ӡ�SEE�ƻ�����2017��10����Ѯ����������16�ڣ���Ծͤ�Ƹ���ˮ400��Ҳ����3�꣬���ۿ�������¥,�ۿ�������͡���
���������˼�ʻ��ͨ���˹�����ϵͳʵ�����˼�ʻ���������������������ǽ�5����ֳ��ӽ�ʵ�û������ƣ����磬�ȸ��Զ���ʻ������2012��5�»�����������Զ���ʻ��������֤��������˹�������˼�ʻ�����Ѿ����г��������ۡ����ż����Ϻ�Ӳ���ϵIJ��Ͻ��������������죬��Ϊ���ڻ�������ͷ�Ķ���Ҫժ�õĹ�ڡ�
����������Ϸ��ָ�dz��˻���������֮���̽�ָ����ǿ���Ļ�������ҵ�������������ҫ�ɶ������Ŷ������¼��ľ��ܿ������ߣ�������˵ʱ�µ�������Լ����ˣ�ͬʱ�����Ż�����IP��ҵ�IJ������չ�����������֡���ѧ�������Ȩ��IP�����ӳ̶�Խ��Խ�ߣ����µĻ�����+ʱ����IP���dz����˶�Ԫ���ķ�չ���ơ�����������������W��ƪ�����е�ռ��������������ԵĿ�����������ҳ�ϵ����¶Ի�������ҵ�����ͷ����ҵ�����϶࣬����Dz��������Ӱ�����֣��������˼�ʻ����ı���ƫ�����⣬�������ⷽ������µı��������첻�ȽϾ��⡣

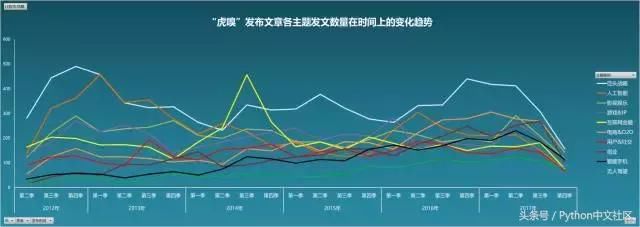
������ͼ�У����ǿ������ԵĿ�������ͷս�ԡ���һ�������ҳ������ʼ��ά����һ���ϸߵ�ˮƽ������ǡ��˹����ܡ��������һ���ȳ���һ������С��ֵ��ע����ǣ������������ڡ���2014���3�����ȵı������ϴ��п��Ի�Ϥ����εĻ���������������һ�������ĽΣ����ʱ�λ�����ҵ���ش��¼��У�С��Ͷ�ʻ�ľ���ӽ������������ڣ�9.10���������������ѽ���ս�ԣ�9.24�������Ͻ�����ų�����10.16�����Լ�����2014���ǡ��ڳ�Ԫ�ꡱ��P2P����ϴ�Ƽ����Լ������ܼ���ֱָ��ܻ��������ڣ���Щ�¼������߶�������������������ʿ�����飬�����һʱ����������Ȼ����
�����������LDA����ģ�ͷ����Ľ��������ʹ����������������������ģ�ͣ���ģ����6����������ϲ�á������ˡ����桢�־�����ԣ�������Щ���µı�����������������ó��������µ�������ǩ������������±���ʾ��
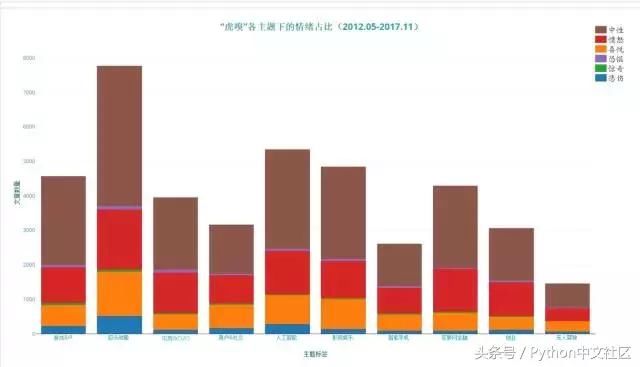
��������ͼ�п��Կ��������������µı��������������Ϊ���������ߺ͵Ŀۺ�����̬�ȣ��������ֽ�����ȫ���ؿ�ζ��ʱ����������ϵĹ�������Ҳ��ζ��ƽ�����棬���Դ������ߵ��Ķ���Ϊ������ν�����Ը��Ʒ�ƣ���������Ӫ�������ܳɹ��������������߾����Ǹ��֣����ԣ�����ͼ�г������������⣬���ڵڶ�λ���ǣ���˺��������ȼ���ߵ��������ٴ��DZ��ˣ�����ʵ�����У��˸���������ͬ���빲����
������������֣��������˽⡰�������ϸ������ҵ�д�����⣬����ijЩţX����ϲ��д�ķ�������£����硰��ҵ���족������ƷӪ������������Ӫ���ȣ����Լ�д���������Ƶ���������Щ��
����Ϊ�ˣ����߲�����ATMģ�ͽ��з�����ע�⣬�ⲻ���Զ�ȡ�������д������author-topicmodel��
����ATMģ�ͣ�author-topic model��Ҳ�ǡ���������ģ�͡������һԱ����LDA����ģ�ͣ�Latent Dirichlet Allocation ������չ�����ܶ�ij�����Ͽ������ߵ�д��������з������ҳ�ij�����ҵ�д�����������Լ��ҵ�����ͬ��д����������ң�����һ����ӱ������̽����ʽ��
�������ȣ�����ȥ�����ɷ���������Ϊ1�����ߣ��ٴ��ı��С��������������⣬��Ϊ�ı�������ɾ�������Ը�֮ǰ�����⻮�ֲ�̫һ�¡����ݸ��������µ���������������߽���10���������Ϊ ������ҵ���š����������ֻ���������ҵ&Ͷ���ʡ��������������ڡ�������&Ӫ��������Ӱ�����֡������˹����ܡ�������ữ������Ͷ����&�������͡��������ۡ���

���������Ǵ��ӿƼ��Ĵ�ʼ�������ƣ�����һֱ��Ϊ����һ�����ˣ�֮ǰ�������ڻ����������������£������뿴���ڻ�������д��ɶ��
����������д�����⼰����ʷֲ����������Ƚ�������д��ҵ�����ʡ������ֻ�����Ӫ����������£�����ȽϷ��ϴ�����֪������黳�Ƶ�����ϲ��̸��ҵ��̸�Լ������ֻ������⣬���������Լ������ĸ��Ժ�Ϭ�������ԣ���������Ϊ�Լ��Ĵ���Ʒ�ƴ��ԡ�
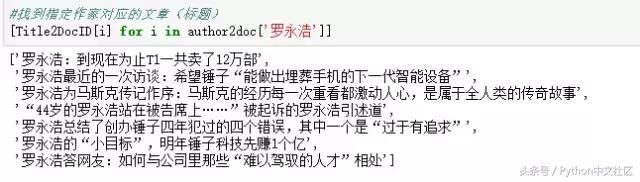

�����������ǻ����Լ��ģ���ҳ�Ϸ������������漰��д�����⼯���ڡ���ҵ���š����������ֻ����͡���&Ӫ������

��������д���������Ƶ����߳���һЩ�������ˣ�������һЩ���绷�������Ƹ���������������ҵ�ܿ��ȡ���ǰ��ķ����п����Ʋ��������������3�������ϵķ�����Ҳ�Ƚϴ�
��������10,189ƪ��������߰��ĵ�ID�����ȡ�����е�����ƪ���µı��⣬������֤�¡�Ȼ����Щ������Ƴɶ�������״�Ĵ��ơ�
������2��ͼ���Կ����������ѧ��ע��������Ҫ�ǡ���ҵ&Ͷ���ʡ�������&Ӫ��������Ļ��⣬ƫ����Ϊ��ҵ���ṩ��ҵ��صļ��ܣ���21���;��ñ������������Ͷ����&������������ҵ���š��͡������ֻ�������Ļ��⣬��ȽϷ��ϸõı������---����������ʽ�����й����á��۲���ҵ��̬���������Է�չ����Ч�ط�ӳ���羭�ø�ּ��仯�������й���ҵ��Ķ�̬�뷢չ��
���������Ƚ����������ı���ʱ��˳��������У��ִʺ��ٽ���Lexical DispersionPlot��������ˣ��ı��������ۻ�����������ʱ���������Ƶķ���һ�¡�ͼ�������ʾ�ʻ㣬�������ı����������ۼӵģ���ɫ���߱�ʾ�ôʻ����ı��б��ἰһ�Σ���Ӧ�����ܿ�������������Ϣ���հ����ʾ���ἰ����ɫ���ߵ��ܼ��̶ȼ�������˸ôʻ���ijһ�ε��ἰƵ�κ��������¡�
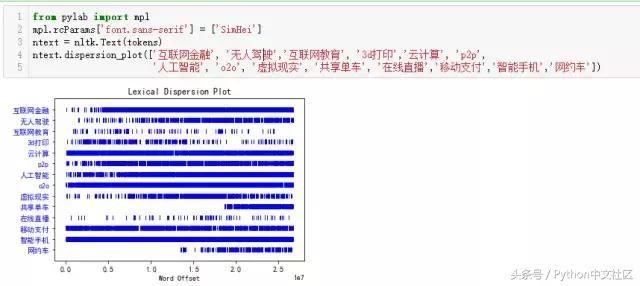
��������ͼ�п��Կ������������ֻ��������ƶ�֧��������O2O���͡��Ƽ��㡱��4�����ڽ�6����ȶȾӸ߲��£��ἰƵ�κܸߣ��������ϼ������͡����֮�£�������������������3D��ӡ����������ֱ������Щ�ڻ������ϵı���������ʼ����ֻ���������ǵ���Щ�ἰ��
����ֵ��ע����ǣ��������������ں����ἰ�����������ӣ������DZ���ʽ�ij��֣����빲���������ֱȽ��Ǻϣ����ڹ���������������ݷ�������ο������ɻ����ô������ı��ھ������조��������������ҵ��״�����ơ���
�����������������Ĵ������ܴӴ���δ��ע����ͨ�ı��������ල��ѧϰ������������Щ�����������˴ʻ���ʻ�֮��������ϵ��������ʵ�����еġ�������ۣ�����Ⱥ�֡�һ�����ʻ�������������ߵĴʻ������壨Words can be defined by the company they keep����
������ԭ���Ͻ������ڴ�Ƕ���Word2vec��ָ��һ��ά��Ϊ���дʵ������ĸ�ά�ռ�Ƕ�뵽һ��ά���͵ö�����������ռ��У�ÿ�����ʻ���鱻ӳ��Ϊʵ�����ϵ���������ÿ�����ʱ��һ��������Ŀ�Ļ���Ϊ�˷�����㣬���硰��A��ͬ��ʡ����Ϳ���ͨ�������뵥��A��cos�����������Ƶ���������������
������������ͨ��Word2vec�����߲��ҳ��Լ�����Ȥ�����ɴʻ�Ĺ����ʣ��Ӷ��ڻ���������������ᄈ��ȥ������ǡ�
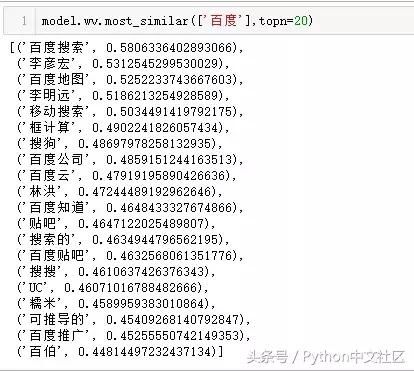
���������Ķ�����ٶ���صĴʻ㣬���ǰٶȵIJ�Ʒ����˾�����ǰٶȵ�CEO�����ߣ������������ֱ���ij����˺ܶ�Σ����ǰٶ���ҵ�һ����
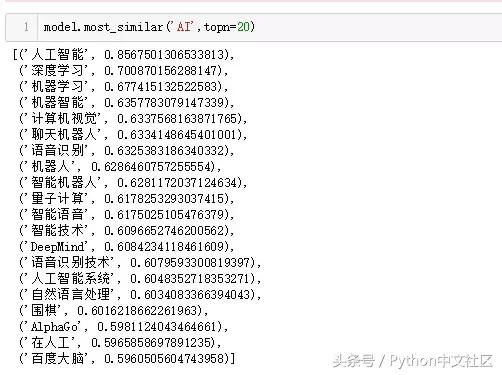
��������ʱ��һ������ش���ǰ��λ���ˣ�ţ��������ѩ�ҡ�³��������������Ҳ������һʱ����ҵ��Ӣ������ү�ӡ��������ϡ������������Ƕ������ơ�����˼���ǣ�����Ҳ��һЩ���ë�ͽ�ίԱ����������Ӣ�����ţ��������´��С�
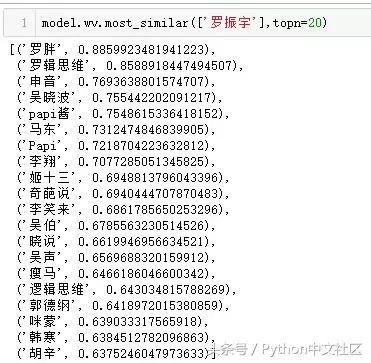
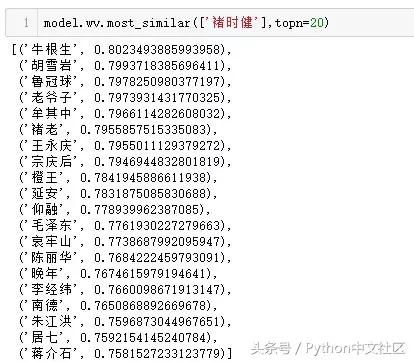
�����پ��������˺�ר���������ˣ���֪ʶ���֡��ļ����ߣ�����������ⶼ��Ⱥ��ԭ�еĹ�������������Ƶ��˻��������������������㡶�ֽܡ��Ĵ�ʼ�˺Ͳ��ˣ�������Ĵ�ҵ��飩����������������Ƶ������Ⱥ�Ĵ�ʼ�ˣ���Papi����֪����Ц���죩���������֡�����˵�������ˣ������裨�õ�APP�ϡ�������ҵ�ڲΡ����Ƴ��ߣ�����ʮ������������ʼ�ˣ�����Ц��������֪�������ߣ����Ⲯ������û��ȫ����21������ҵ���ۡ������ˣ���Ʒ�С����⡷�͡�������֪¼������
����2016�껥������ǿ��ҵ�Ļ�����ҵ�������ܹ�ģ�ﵽ1.07����Ԫ���״�ͻ�����ڴ�أ�ͬ������46.8%��������Ϣ��������8.73%��������ʾ��������������ͷ��ҵЧӦԽ��Խ���ԣ������ǵ��о������ܰ������Ǹ��õ��˽��й���������ҵ�ķ�չ�ſ���δ������
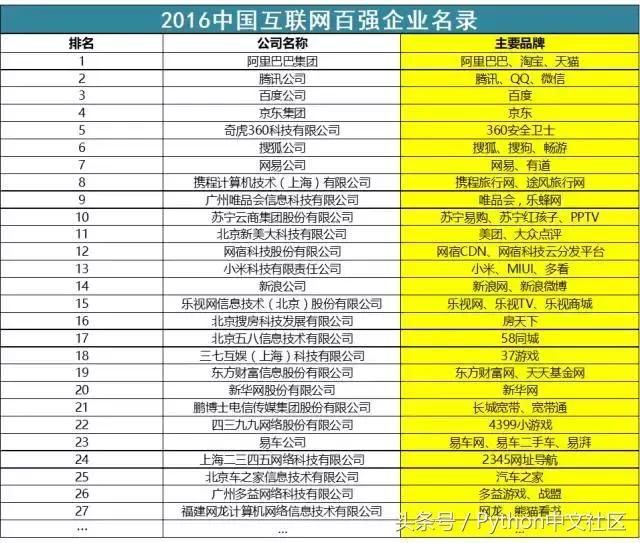
��������������ǿ��������˾������Ʒ����¼����������ѵ�������Ĵ�����ģ�ͣ�������������Ĵʾ���ʹʷ��ࡣ
�������û���Word2Vec������������K-Means���࣬��ֿ����˴ʻ�֮��������ϵ�������Ҽн�ֵ��С�Ĵʻ�ۼ���һ���γɴ�Ⱥ����ͼ�Ǹ�ά������ѹ����2ά�ռ�Ŀ��ӻ����֣�
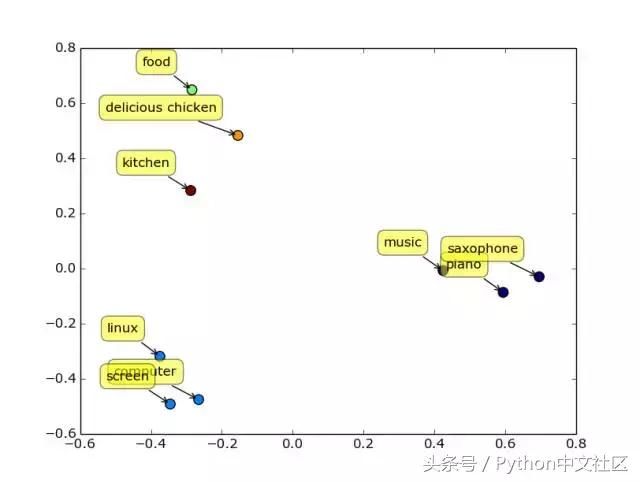
�������߽�������ģ���������������дʻ㻮��Ϊ300����𣬿��������趨�µ�Ʒ�ƾ���Ч����Ρ������������������ʾ��


���������������������Щ�����DZȽϺ�����ģ���;�磨������¿���������������������εģ����˴���½���������Ĵ��Ǹ㻥��ģ���Щ�ʻ����ڡ�
����������ֵĴ����϶࣬����ͬ���ϵ������һ��ͬ��һ����ҵ�������д�����ľ���ǰ���ҵ���ģ������������ᄈ�г��֣��ҿ����������λ�����һ���˿ں����Ǵ�2011�꿪ʼ�ģ��Ⲩ�˿���ԭ�����ĵ������ضȻ�����������˵�����Ǹ����ȥ��
�����ֻ���iPhone���Ⲩ�û�����ȻҲ�������ǡ�������һ���߳�����߱Ƚ�ƫ�������Щ�˿ڡ������㿴���������Լ�Ͷ�ʵ���ͼ��֪��������ͷ����С���Ǹ����Ⲩ�˿������ġ��ڶ����˿��Ǵ�2013�ꡢ2014�꿪ʼ�����ģ��Ⲩ�˿���ʲô���Ⲩ�˿�ʵ�������ƶ��������������߳����³���ɵ��˿ں������Ƕ������߳�������Ƚ�������˿ڡ���Ҽ���һ����
������ViVO�ֻ����ˡ��Ⲩ���������˰������֡�ӳ�͵�һϵ�е����𣬰������Ķ������𡣼ӴּӺڵ�Ʒ����Ȼ��ͬ��һ����ҵ�����������ڡ�
�������������������֮ǰѵ���ó��Ĵ�������ͨ������CNN�� ConvolutionalNeural Networks�����������磩���ı����࣬����Ԥ�⡣CNN�ľ���ԭ��̫�����ӣ����������ﲻ����������Ȥ��С�����Բ��ĺ���ġ�

���������ı����ࣨText Classification�������ı����ࣨText Cluster���ڻ���ѧϰ�з�����ͬ������ǰ�����мල��ѧϰ������ѵ�����ݶ��б�ǩ�����������ල��ѧϰ������û�б�ǩ�����������������ʽ���ı���������ʼǰ�������б�ע������ѵ��ģ�ͣ�����Ԥ�������δ֪���ı���
������������߸��ݻ�������ҵ����ϸ������IJ�ͬ������Ϊ17�����ÿ�����ֻ�к��ٵı�ע���ϲ���ѵ����Ҳ���Ǽ����ʰ��ˡ��ԣ���û�����������ⲿ������Ϣ��֮ǰѵ���õĴ�����ģ�ͣ��Ѿ������д�����������Ϣ������ֻ��Ҫ�����ı�ע���ϾͿ�����ɷ���ģ�͵�ѵ����

�������ţ�������֮ǰδ������ѵ�������еĴ�������Ч���������Ľ��������ǩ�����Ӧ�ĸ��ʣ�����ֵ��������Ʒ�����п��ܴ�����ϸ�����������ͼ��ʾ��
���������Ľ�������ϴ�ҵĻ�����֪��С��ģ�����£�ȷ���пɣ������һ���Ѷȴ�һ��ģ�����һ�ұ��ߴ�δ֪���Ļ�������˾��
������ͼ�ĿƼ���˾��ǰһ��ʱ�����һ�ѣ���Google 10����Ԫ�չ��ˡ����Ʒ��Ȼû��Google��ͼ����ǿ�������ͼƬ��֧�ţ����ǿ������û������ṩ�йؽ�ͨ״������ͨ�¹��Լ���������ʵʱ��Ϣ����ͼ��Ļ���ӸУ������ڰ����͡�ʵʱ��Ϣ���ֱ��Ӧ���������á��͡���ʱͨѶ�����ȽϷ���Ԥ���ǩ���������ں�������һ���̶���Ԥ�������ҵ��ҵ�����ԡ�
���������Ĺ��ڻ�������ǿ��˾�ľ�������ͷ���������������ǡ���ϻ�ӡ��������ڵĻ��������Dz�̫�������⡣�����������߽����ڡ�ͼ�ۡ�����Ʒ�ƹ��ַ�����������ĽǶ���������ǿ��ҵƷ��֮��Ĺ�����ϵ��

������ͼ�У�ÿ���ڵ����һ�����������ϸ����Ʒ����Ʒ��֮���ǿ�����ӹ�ϵ����ͬ��ɫ�Ľڵ��ʾ���ǣ���ij�������£�ͬ����һ�ࡣ�ڵ㼰����Ĵ�С��ʾƷ���������е�Ӱ������С��Ҳ���ǡ�Betweenness Centrality���н�ˣ�����ѧ����˵���ǡ�
��������˵�˻����ǣ������Ӱ��������ζ�Ÿ�Ʒ�������˸���ĺ����������Դ���Լ��������Ļ����������ȿ�����Ӱ����TOP10����������Ѷ���š��ٶȡ�QQ������Ͱ͡��Ա���������С�ס�����������������Ѷϵ����10ǿ��ռ����3��ϯλ��ʵ��ǿ�ɼ�һ�ߡ�
����ֵ��ע����ǣ�����ϵ��С�ס����MIUI�������Ķ�����С��Ϊ����MIUI��С�IJ�Ʒ������Ķ����Ѿ���С���չ��������Ķ�һ����С���Ķ�������Ȼ������ţ��Ϸ��ǰ������ͬ����һƪ���µı����������ģ�����ţ�����ƶ�ս�ԣ�ʯ��������С�ڶ���������С�����ƶ���Ϸ����Ķ��֡�
�������⣬����ϵ����Ѷ���š��ٶȡ�QQ�����ס��Ѻ��ȣ������ϵ������Ͱ͡��Ա�������������������è�ȣ���������Ⱥ�У�Ʒ����Ʒ��֮��Ĺ�ϵ�ͱȽϸ����ˣ���ĸ��˾���ֵ�Ʒ�ơ������������Թ�ϵ����羺�������ʼ��沢��������������������Ⱥ�л�ɼ����֮��
�����ڱ��ĵ��ı��ھ֣���ʵ�Ѿ��漰���˹�����/AI����ʵ��Ӧ��---�ؼ�����ȡ��LDA����ģ�͡�ATMģ�����ڻ���ѧϰ���������������������ʾ���ʹʷ����漰�����ѧϰ�����֪ʶ����Щ����AI �����ݷ����е���ʵӦ�ó�����
�������⣬������̽�����ʵ����ݷ����ɻ��ģ��������ݷ������棬��������˼���������棬�ó�����Ľ��۲��DZ��ĵ�Ŀ�ģ��Խ���ķ�����ɢ�ڸ������֣�����ĩ���ۿء���ϲ���硣
����
������£�
- ���ھ�����4��ƪ����չ���й�����������
- ��36���� ��Ѷ��������������Ϊ�쵼������ޡ�
- ������IT��ҵ��չ���桷�� ȫ��Լ�߳����ܡ�
- �����ڳ�Ϊȫ��IT��ҵ����ȥ���ֵ��241����Ԫ��
- �������Ϫ�������ϲ�ҵ������ֵDZ�� �����ġ�
- �����������
- ������ͷ������˦���� �ϸ��ܱ��Ծ�����Ч
- ������R1��վ���ڲ��ع� ���ߴ�����������
- ��ïҵͨ�ţ�����������˾���Ƽ�����˾�¡�
- ����ѵ��������Ӫ��ȫ����������1841TB